Extract Smarter: How Domain-Aware AI Builds Better Knowledge Graphs
Most AI extraction tools treat every document the same way. Upload a medical paper or a legal contract and you get the same generic entity types, the same vague relationships, the same disappointing graph. Chaos Cypher takes a different approach: it detects what kind of document you uploaded and adapts its entire extraction pipeline to match.
The Problem with Generic Extraction
Here's a sentence you might find in a clinical document:
Patient with hypertension started on lisinopril 10mg daily. The ACE inhibitor is contraindicated with potassium supplements. Side effects include dry cough and dizziness.
A generic extraction pipeline -- the kind most tools use -- will pull out a handful of entities and connect them with whatever relationship labels the LLM feels like inventing. You might get "Lisinopril" typed as an Item, "Hypertension" as a Concept, and "Dry Cough" as another Concept. The relationships between them? Probably related_to and influences. Maybe associated_with if you are lucky.
This is the "garbage in, garbage out" of knowledge graphs. It's not that the AI failed to read the text. It read it fine. The problem is that nobody told it what to look for, what types are valid, or what the relationships between those types should mean.
The graph you get is technically correct and practically useless. You cannot query "which drugs treat hypertension" because the system does not know what a Drug is. You cannot find contraindications because related_to could mean anything. Every edge in the graph carries the same semantic weight as a shrug.
Now run the same sentence through Chaos Cypher with the medical domain active:
- Lisinopril becomes a Drug with dosage form and mechanism of action as properties
- Hypertension becomes a Condition
- Dry Cough and Dizziness become Side Effects
- Potassium Supplements gets recognized as a Drug (because supplements have drug interactions too)
The relationships are just as precise: treats, contraindicated_with, produces_side_effect. Each one is typed, directional, and constrained. A treats edge must start from a therapeutic agent (Drug, Treatment, Procedure, Protocol, or Guideline) and land on a clinical target (Condition, Symptom, Side Effect, Pathogen, or Patient Population). A Side Effect can never treat a Drug. The LLM isn't guessing -- it's following a schema.
That's what domain-aware extraction does. It turns a language model from a general-purpose pattern matcher into a domain specialist.
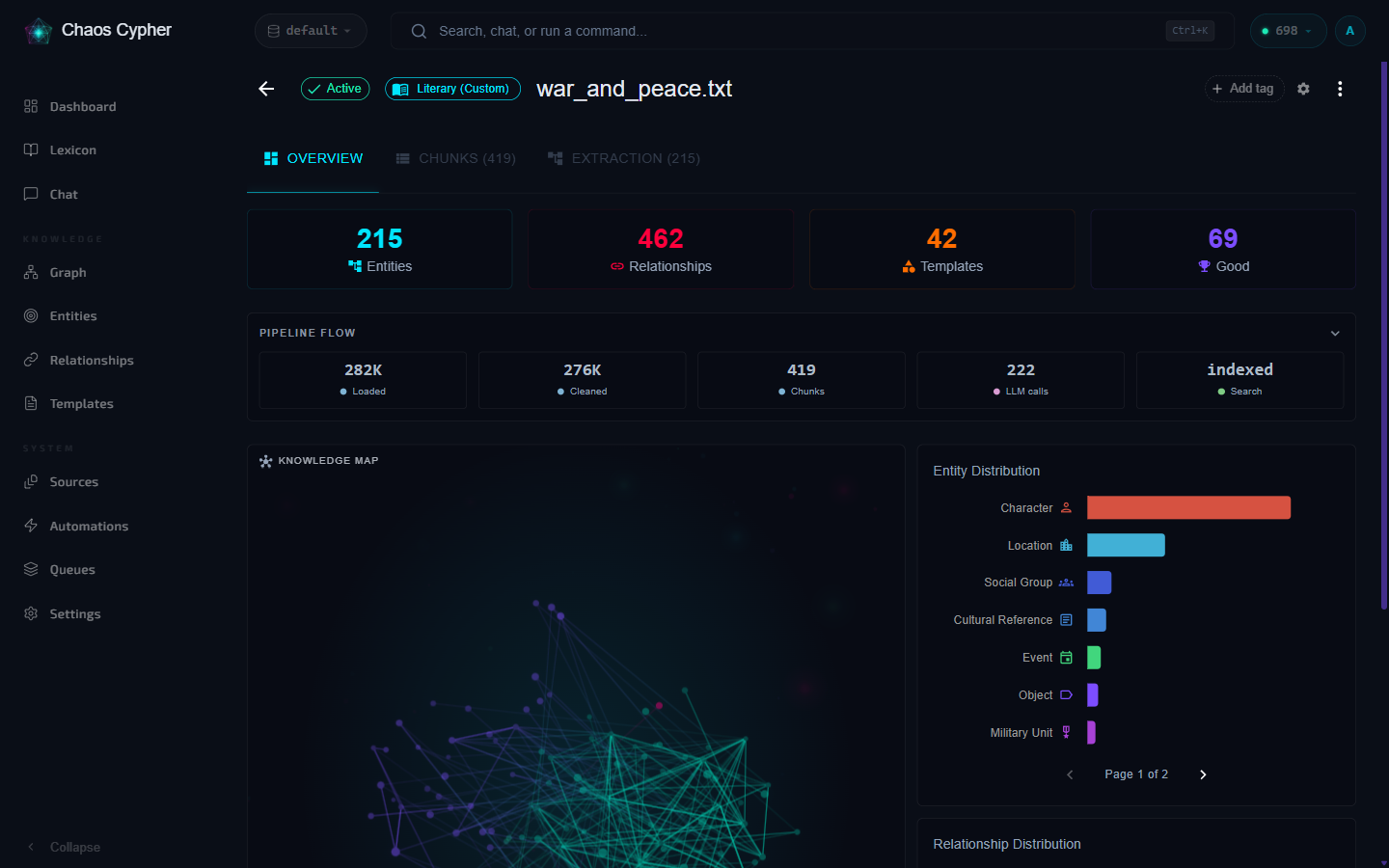
How It Works: Upload to Knowledge Graph
The workflow is straightforward. You upload a document. Chaos Cypher figures out what domain it belongs to, loads the right extraction rules, proposes the domain for your confirmation, then runs the pipeline. You don't need to configure anything upfront -- though you can override the detected domain if you want.
Since the domain-confirmation gate shipped, auto-detection proposes a domain and parks the source awaiting your one-click confirmation before the (potentially hour-long) extraction runs. You can accept, override the proposed domain, or pass auto_confirm at upload to restore the fully hands-off behavior described below.
Here's what happens behind the scenes:
-
Detection -- Chaos Cypher samples up to ~12,000 characters drawn from the beginning and the middle of your document and scores it against all registered domains simultaneously. Each domain has weighted keyword groups, regex patterns, and file type signals. The highest-scoring domain wins.
-
Guidance injection -- The winning domain's extraction rules get injected into the LLM prompt. This includes entity type definitions, relationship constraints, exclusion rules (what not to extract), and worked examples of correct extractions.
-
Strict type enforcement -- The LLM is instructed to only use entity types from the domain's template list. After extraction, a code-level filter drops any entity whose type does not match a known template. No hallucinated types survive.
-
Relationship validation -- Each relationship is checked against source/target type constraints. A
treatsrelationship must flow from a therapeutic agent like a Drug, Treatment, or Procedure to a clinical target like a Condition or Symptom. Anything else gets rejected. -
Quality scoring -- Extracted entities and relationships are scored by domain relevance. Domain-specific types like Drug and Condition score higher than generic fallbacks. This surfaces the most valuable parts of your graph.
Chaos Cypher ships with 19 built-in domains, each tuned for a different category of document. A sample:
| Domain | Typical Entity Types | Best For |
|---|---|---|
| Medical | Drug, Condition, Symptom, Procedure, Side Effect | Clinical documents, pharmaceutical literature |
| Technical | Module, Class, Function, Endpoint, Design Pattern | API docs, codebases, technical specifications |
| Legal | Statute, Case, Party, Obligation, Legal Principle | Contracts, court opinions, regulatory filings |
| Financial | Company, Financial Instrument, Market Event, Regulation | Earnings reports, market analysis, SEC filings |
| Scientific | Hypothesis, Method, Finding, Dataset, Organism | Research papers, experiments, academic publications |
| Cybersecurity | Threat Actor, Vulnerability, Malware, Attack Technique | Threat intel, incident reports, CVE research |
| Generic | Person, Organization, Event, Concept, Location | General-purpose fallback for any content |
The rest cover historical, literary, theological, investigative, political, design, intelligence, news, educational, philosophical, biographical, and reference material — the full list with every entity type is in the docs.
Every domain uses strict entity type enforcement by default. The medical domain defines 20 entity types. The technical domain has 18. These aren't suggestions -- they're the only types the LLM is allowed to produce. That constraint is what separates a clean, queryable graph from a noisy soup of ad-hoc labels.
Under the Hood: Domain Detection and Extraction Quality
How Detection Works
Domain detection runs a scoring algorithm across all registered domains simultaneously. Each domain defines its detection rules in a JSON-LD config file with three signal types:
Weighted keyword groups. The medical domain has six keyword groups: clinical_core (weight 1.2), pharmaceutical (weight 1.0), diagnostic (weight 0.9), anatomy (weight 0.8), procedures (weight 0.9), and clinical_terms (weight 0.8). Each keyword match boosts the confidence score by per_keyword_boost * weight. A document full of "diagnosis", "treatment", and "symptoms" racks up points fast in the clinical_core group, while scattered mentions of "cardiac" and "pulmonary" add smaller anatomy-weighted boosts.
Regex patterns. Keywords catch common terms, but patterns catch domain-specific notation. The medical domain matches dosage expressions like \d+\s*(mg|mcg|ml), ICD codes like ICD-10:J45, and prescription abbreviations like b.i.d. and p.r.n.. Each pattern match carries its own weight -- dosage notation at 1.4x, ICD codes at 1.5x. A single ICD code in a document is a strong medical signal.
File and document type signals. File extensions (.py for technical) and document type metadata (medical_document, openapi) provide additional boosts.
The final confidence score is compared against a per-domain minimum threshold. Medical requires 0.4 minimum confidence. The generic domain has a threshold of 0.0 -- it always matches as a fallback, but with the lowest possible score (0.1), so any specialized domain that passes both its own minimum threshold and the registry's absolute confidence floor of 1.0 will win. The floor exists so weak, ambiguous matches fall back to the broad generic schema instead of locking in a wrong domain.
How Domains Shape Extraction Quality
Detection picks the right domain. But the real value is in what happens next -- the selected domain controls the extraction pipeline at five points:
- Entity guidance tells the LLM what to extract and what to skip. The medical domain says "include dosage information as properties on drug entities" and explicitly excludes standalone dosage numbers, study references ("Figure 1"), and administrative codes.
- Strict type enforcement gives the LLM a closed list of valid types -- the medical domain allows exactly 20. Anything outside that list gets dropped in post-processing. No more "Medical Concept" or "Health Thing" cluttering your graph.
- Relationship constraints validate source and target:
treatsmust flow from a therapeutic agent like a Drug, Treatment, or Procedure to a clinical target like a Condition or Symptom. A Symptom that "treats" a Drug fails validation. This catches the most common extraction error -- reversed or nonsensical edges. - Compatibility groups handle deduplication: "Hypertension" extracted as a Condition in one chunk and a vaguer type in another can be merged because both belong to the
clinicalgroup -- no duplicates, no lost type precision. - Property type mapping rescues mistyped entities: "Severity" extracted as a standalone node gets absorbed into the right Condition as a
severityproperty instead of floating as an orphan.
In plain English: the domain is a contract. The LLM does the reading, but the domain decides what counts as a valid entity, a valid relationship, and a valid graph -- and everything that breaks the contract is filtered out before it reaches you.
Try It Yourself
Every built-in domain is just a JSON-LD file. No Python, no compilation, no framework code. If you need a domain for your field that doesn't exist yet, you can create one in about 20 minutes: drop a file in data/plugins/domains/, define your detection signals and your vocabulary, restart, done.
Say you want a startup domain for pitch decks and funding announcements. The skeleton is just three parts -- how to recognize the content, what entities exist, and how they're allowed to connect:
{
"@type": "ExtractionDomain",
"name": "startup",
"strict_entity_types": true,
"detection": {
"confidence": { "base_score": 0.2, "per_keyword_boost": 0.12 },
"keywords": {
"funding": {
"terms": ["series A", "series B", "seed round", "venture capital",
"valuation", "term sheet", "cap table", "pre-money"],
"weight": 1.3
}
},
"patterns": [{ "regex": "\\$\\d+[MBK]\\s+(seed|series|round)", "weight": 1.5 }]
},
"templates": {
"node_templates": [
{ "id": "startup_company", "name": "Company" },
{ "id": "startup_round", "name": "Funding Round" }
],
"edge_templates": [
{ "id": "startup_raised", "name": "raised",
"source_types": ["Company"], "target_types": ["Funding Round"] }
]
}
}
Detection has an absolute confidence floor of 1.0 -- a domain that scores below it loses to the generic fallback, so give a new domain enough keyword surface to clear it, or force the domain at upload while you tune detection. (The skeleton above clears it: eight keywords at a 0.12 boost and 1.3 weight put a keyword-rich article at roughly 1.45 before patterns even fire.)
Upload a TechCrunch article and watch the detection engine propose it at the confirmation step: confirm, and Companies and Funding Rounds appear in your graph, connected only by the relationships you allowed.
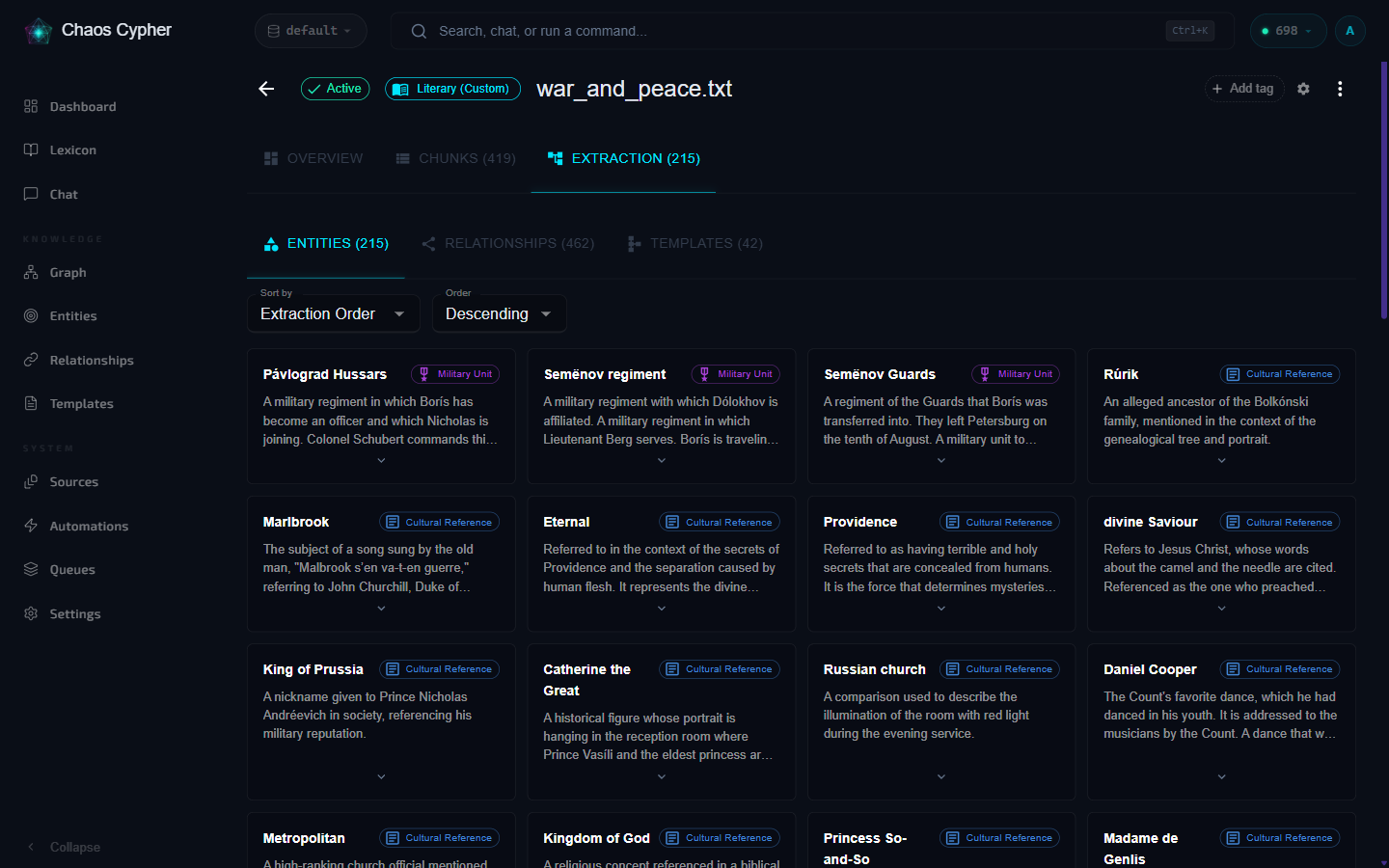
The full walkthrough -- weighted keyword groups, named-referent flags, entity properties, inverse relationships, and a complete worked example -- lives in the docs: start with Custom Domains, then Building Extraction Domains for the whole schema, including normalization keywords, compatibility groups, property absorption, and extraction-density tuning. The built-in medical domain is the most comprehensive reference -- study it when you want the full picture.
What's Next
We're planning more specialized domains -- supply chain, environmental science, and music theory are on the shortlist. But the real potential is in what users build. Every field has its own vocabulary, its own entity types, its own relationship patterns. A materials scientist cares about Crystal Structure, Synthesis Method, and Property. A genealogist needs Person, Family, Vital Record, and Census Entry. A cybersecurity analyst -- who already has a built-in domain -- might want to fork it and add types specific to their organization's threat model.
If you build a domain for your field, share it. A JSON-LD file is small, portable, and easy to review. Drop it in data/plugins/domains/ and it works. No pull request required to use it, but we would love to include community domains in the built-in set for others to benefit from.
Domains work identically whether you're running locally with Ollama or with a cloud provider. Start with the skeleton above, test it on your documents, and iterate from there.