Why Your RAG Chat is Missing Half the Answers (And How GraphRAG Fixes It)
You upload four research papers to your RAG chatbot. You ask: "How does Dr. Chen's CRISPR research connect to the gene therapy trials at Stanford?" The chatbot thinks for a moment and gives you... a paragraph about CRISPR. Generic, shallow, pulled from whichever single chunk happened to mention the word. The actual answer -- that Chen published a paper on CRISPR delivery mechanisms, which was cited by a Stanford clinical trial for retinal gene therapy, which built on a funding collaboration between both institutions -- exists across three different documents. Your chatbot never even tried to find it.
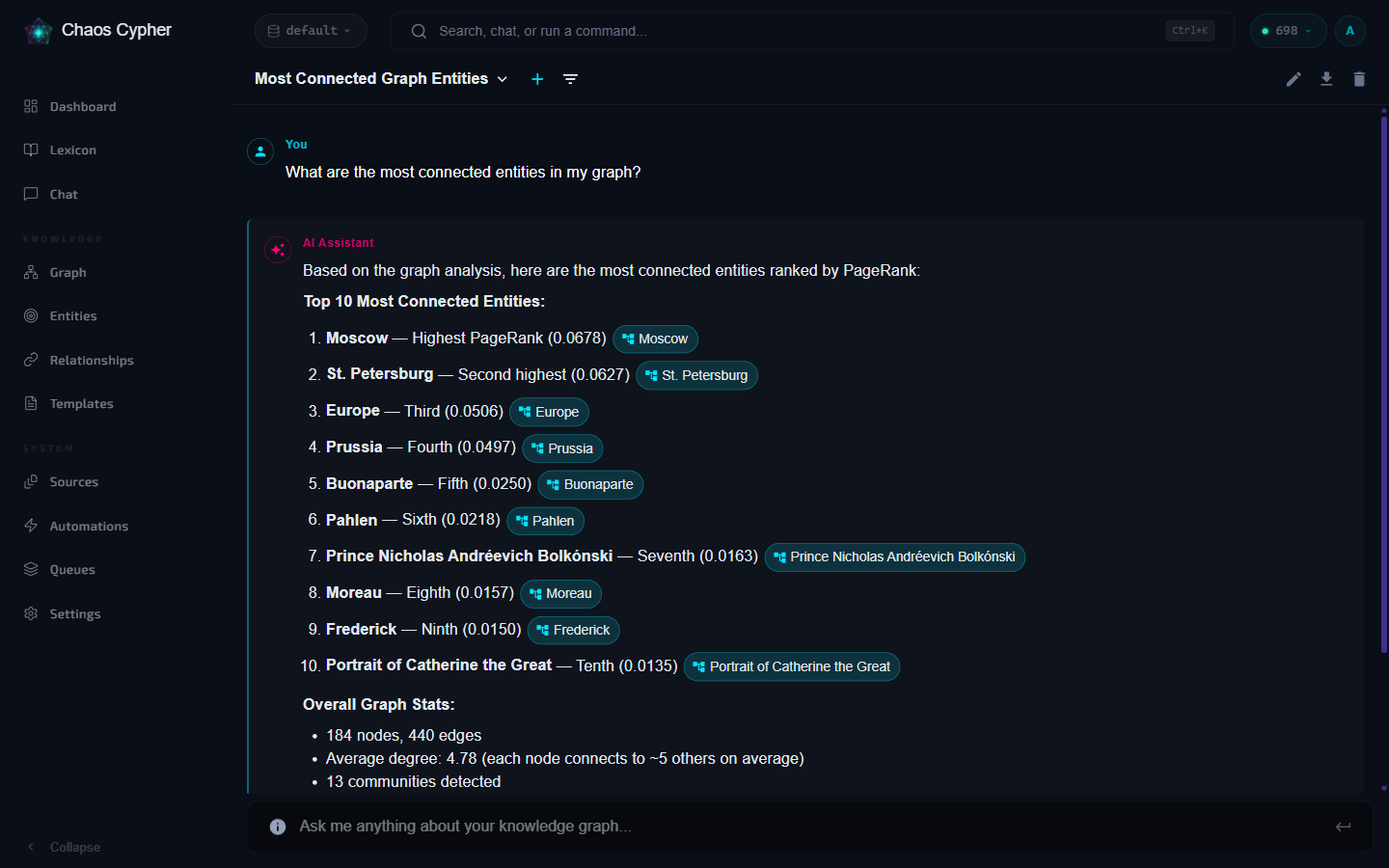
This is the multi-hop problem, and it's the silent failure mode of every vector-only RAG system. Vector search embeds your question, compares it against document chunks, and returns the closest matches by cosine similarity. It works for single-hop questions: "What is CRISPR?" or "When did the Stanford trial begin?" But the moment an answer requires connecting information across documents -- following a citation chain, tracing a person through multiple sources, linking a cause in one report to an effect in another -- vector search falls apart. It can't follow relationships. It doesn't know that entities in different documents refer to the same thing. It just sees text. In an independent benchmark, GraphRAG-style retrieval scored 53% vs 43% for reranked vector RAG on complex multi-hop reasoning (GraphRAG-Bench, ICLR 2026).
The worst part: it fails silently. No error message, no "I couldn't find a complete answer." You get a confident-sounding response that happens to be shallow or wrong.
Chaos Cypher's GraphRAG search fixes this by fusing knowledge graph traversal with vector search. When you ask a multi-hop question, it walks the graph of entities and relationships extracted from your documents, finds structurally connected information you didn't ask about, retrieves the source passages that prove those connections, and merges everything into a single ranked result set. The answer you get isn't just semantically similar text. It's the actual chain of evidence.
What Happens When You Ask a Multi-Hop Question
Let's walk through a real scenario. You have uploaded three documents into Chaos Cypher: a research paper by Dr. Sarah Chen on CRISPR delivery vectors, a Stanford clinical trial report on retinal gene therapy, and a grant proposal connecting both institutions. You type into the chat: "How does Chen's CRISPR work relate to the Stanford gene therapy trial?"
Here's what happens behind the scenes, in seven steps.
Step 1: Embed the query. Your question gets converted into a vector embedding -- the same starting point as any RAG system.
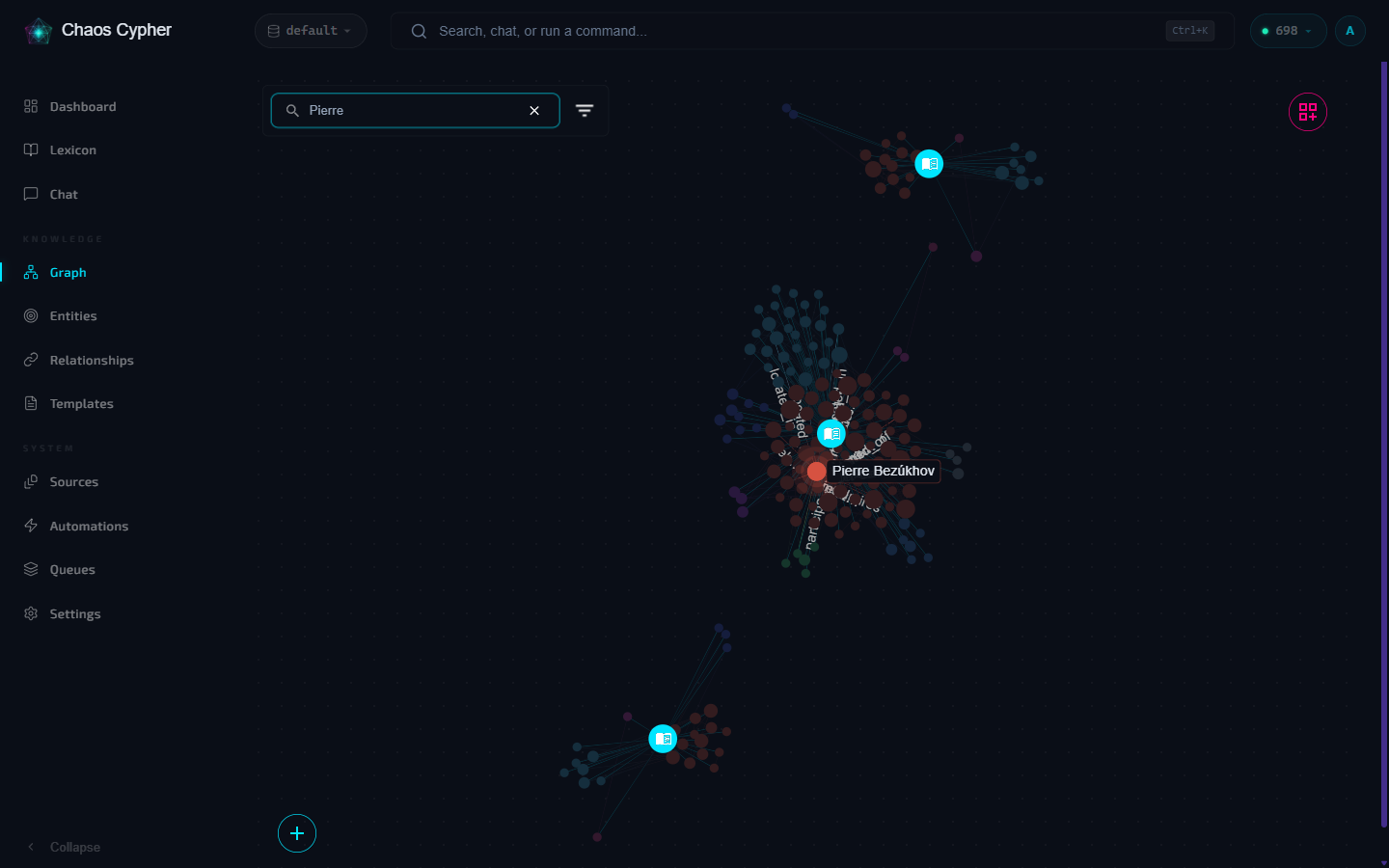
Step 2: Match seed entities. Instead of immediately searching document chunks, GraphRAG first searches the knowledge graph. It finds entities whose embeddings are closest to your query vector. In this case, it matches "Dr. Sarah Chen" (a Person node) and "CRISPR delivery vectors" (a Concept node) as high-confidence seeds -- the anchor points for graph exploration.
Step 3: Personalized PageRank. This is where it gets interesting. Standard PageRank finds globally important nodes. Personalized PageRank is different: it starts from your seed entities and performs a biased random walk through the graph. At each step, there is an 85% chance of following a relationship to a neighbor, and a 15% chance of teleporting back to a seed. Entities structurally close to your seeds get high scores, even if they were never mentioned in your query.
In our example, the algorithm discovers that "Dr. Sarah Chen" has a "published" relationship to "Lipid Nanoparticle Delivery Study," which has a "cited_by" edge pointing to "Stanford Retinal Gene Therapy Trial Phase II," which in turn has a "funded_by" connection to "NIH CRISPR Therapeutics Grant" -- a grant that also lists Chen as a co-investigator. None of these intermediate entities matched your query by text similarity. The graph surfaced them.
Step 4: Assemble graph context. The top-scoring entities from PageRank are collected along with their relationships. This produces a structured context: seed entities you asked about, related entities the graph discovered, and the relationship triples connecting them. This context gets passed to the language model alongside the document chunks, giving it the structural "map" it needs to reason about connections.
Step 5: Retrieve provenance chunks. The first of two independent retrieval paths. For each entity the graph surfaced, GraphRAG looks up which document chunks those entities were originally extracted from. Chen was extracted from page 3 of the research paper. The Stanford trial came from the clinical report abstract. The funding connection came from page 12 of the grant proposal. These "provenance chunks" contain the actual evidence for the graph relationships.
Step 6: Retrieve vector chunks. The second path runs next -- standard hybrid search (semantic + keyword) against all document chunks. It catches relevant passages that might not have generated graph entities but still contain useful context.
Step 7: Merge and rank. The two paths produce two independently ranked lists. GraphRAG merges them using Reciprocal Rank Fusion, which combines rankings without normalizing scores across systems. Chunks appearing in both lists get a combined boost. The result is a single, deduplicated, ranked list of the most relevant passages across all your documents.
Instead of a shallow answer about CRISPR, you get the full chain: Chen's delivery mechanism research led to a cited clinical application at Stanford, connected through shared funding. The chat response includes both the graph context (discovered entities and relationships) and the document passages that prove those connections.
Under the Hood (Technical Deep-Dive)
This section is for developers who want to understand the algorithms. Skip ahead to "Try It Yourself" if you just want to use it.
Personalized PageRank
Standard PageRank models a "random surfer" following links uniformly across a network. Personalized PageRank changes one thing: instead of teleporting to a random node, the surfer teleports back to seed nodes. This transforms a global importance metric into a query-specific relevance metric.
Chaos Cypher's implementation uses rustworkx's compiled power iteration with a 0.85 damping factor and runs entirely in-process -- no external graph database or service required. The seed weights come from the vector similarity scores in Step 2, so the random walk isn't just seeded on the right entities -- it's biased toward the ones most relevant to your specific question.
Reciprocal Rank Fusion
Provenance chunks have graph-connectivity scores. Vector chunks have cosine similarity scores. These aren't on the same scale, so you can't just sort by score.
RRF (Cormack, Clarke & Butt, 2009) sidesteps this by ignoring scores entirely and using only rank positions. Each chunk's RRF score is the sum of 1 / (k + rank) across all lists where it appears. The smoothing constant k (60, matching the original paper) dampens the advantage of being ranked first versus second.
The key property: chunks appearing in both lists get contributions from both, naturally boosting results validated by two independent signals. A chunk ranked 5th in provenance and 8th in vector search will often outrank one that is 1st in vector but absent from provenance. Evidence confirmed by graph structure is worth more than text similarity alone.
Graceful Degradation
Not every database has a knowledge graph. Not every query matches graph entities. GraphRAG picks its operating mode automatically:
full_graphrag-- Seeds found, PPR succeeded. Graph context + provenance chunks + vector chunks + RRF fusion.vector_only-- Embeddings work but no graph seeds found. Standard hybrid search, no graph context.keyword_only-- Embeddings unavailable. Pure SQLite FTS keyword search.
The system never fails -- it always returns the best results it can. The retrieval stats in each response tell you exactly what happened: mode used, seeds found, entities explored, provenance versus vector chunk counts.
In plain English: the graph finds the path between things you asked about, the vector index finds text that sounds like your question, and the fusion step trusts evidence confirmed by both more than either alone.
Try It Yourself
Here's the good news: you don't need to configure anything. GraphRAG is the default search mode behind every chat conversation in Chaos Cypher. When you type a question, the chat system prioritizes graphrag_search as its first tool for most questions. If your database has extracted entities and embeddings, you get the full pipeline. If not, it degrades gracefully to vector or keyword search.
The simplest way to see it in action:
-
Upload 3-4 related documents. Pick sources that share entities -- research papers from the same field, chapters from the same book, reports about the same project. The key is overlap: the documents should reference some of the same people, organizations, concepts, or events.
-
Wait for extraction to complete. Chaos Cypher will chunk the documents, generate embeddings (automatic), and then you can optionally run entity extraction to build the knowledge graph. (Update, May 2026: extraction now auto-detects your document's domain first and asks you to confirm it before the run starts -- you can also pre-confirm in the upload dialog.) The extraction step is what creates the graph nodes and edges that GraphRAG traverses. Without it, you still get vector-only search, which is fine -- but you miss the multi-hop connections.
-
Ask a question that spans documents. Don't ask something that a single document can answer. Ask about connections: "How does X relate to Y?" or "What is the link between the findings in paper A and the methodology in paper B?" This is where GraphRAG earns its keep.
-
Check the retrieval stats. In the chat response metadata, you'll see the retrieval mode (
full_graphrag,vector_only, orkeyword_only), the number of seed entities found, how many entities PageRank explored, and the breakdown of provenance versus vector chunks. This tells you exactly what the pipeline did for your query.
GraphRAG is also available as an MCP tool called graphrag_search, meaning any AI assistant that supports MCP can use it directly against your Chaos Cypher instance. See our MCP launch post for setup instructions with Claude Desktop, Cursor, and others.
The pipeline is tunable -- seed similarity threshold, PageRank top-K and damping, triple limits -- via a graphrag section in settings.yaml, though the defaults were chosen from the GraphRAG literature and testing across database sizes, and most users will never need to touch them. The full parameter reference is in the search documentation.
What's Next
GraphRAG in Chaos Cypher today handles local queries well -- questions where you have a specific starting point and want to follow connections outward. But there's a class of questions it doesn't yet handle optimally: corpus-wide questions like "What are the main themes across all my documents?" or "Summarize everything related to sustainability."
These require what the research literature calls community summaries -- pre-computed summaries of entity clusters in the graph that can answer high-level questions without traversing the entire structure at query time. That's on the roadmap.
If you're working with a use case where multi-hop retrieval matters -- legal discovery, academic research, intelligence analysis, medical literature review -- we'd love to hear about your experience. What kinds of multi-hop questions does your work require? Where does the current pipeline fall short? The best way to reach us is through the project's GitHub discussions.
For a deeper look at the architecture, see the Search documentation and the Architecture overview.